
A web scraper is used to automatically retrieve data from websites. This data can then be utilized for various purposes. In many cases the data is used for apps. We describe how to build a web scraper in C#. You can find the source code of this Demo web scraper at the end of the post.
What is the difference between web scrapers and web crawlers? A web scraper pulls certain information from a website. Crawlers, such as Google Crawlers, search the internet and follow every link they can find to create databases with the sub-pages of websites. Then they also scrape for certain information.
List of components
- Vistual studio (free)
- Webbrowser (Chrome or Brave)
Importing the HTML page source
At first, open Visual Studio, click on Create new project and select “Console app (.NET Core)”. This is the easiest way to demonstrate how a web scraper works. Next, we need a website from which we want to pull information. This website will be our article about programming an Android application to control an Arduino: https://nerd-corner.com/android-bluetooth-classic-app-for-arduino-fan-control/.
Every website is an HTML document. We load this HTML page source into our .NET application and automatically search for information that interests us.
In Visual Studio click on “Manage NuGet Packets” and add the HtmlAgilityPack. Define the main function as “async” and a variable “url” that contains the link to the website. Then add “System.Net.Http;” as using directive and create a new HttpClient “var httpClient = new HttpClient ();”. Now we can access the HTML data of the website: “var html = await httpClient.GetStringAsync (url);” and store it in a variable which we define as HTML document: “var doc = new HtmlDocument (); doc.LoadHtml (html);”.
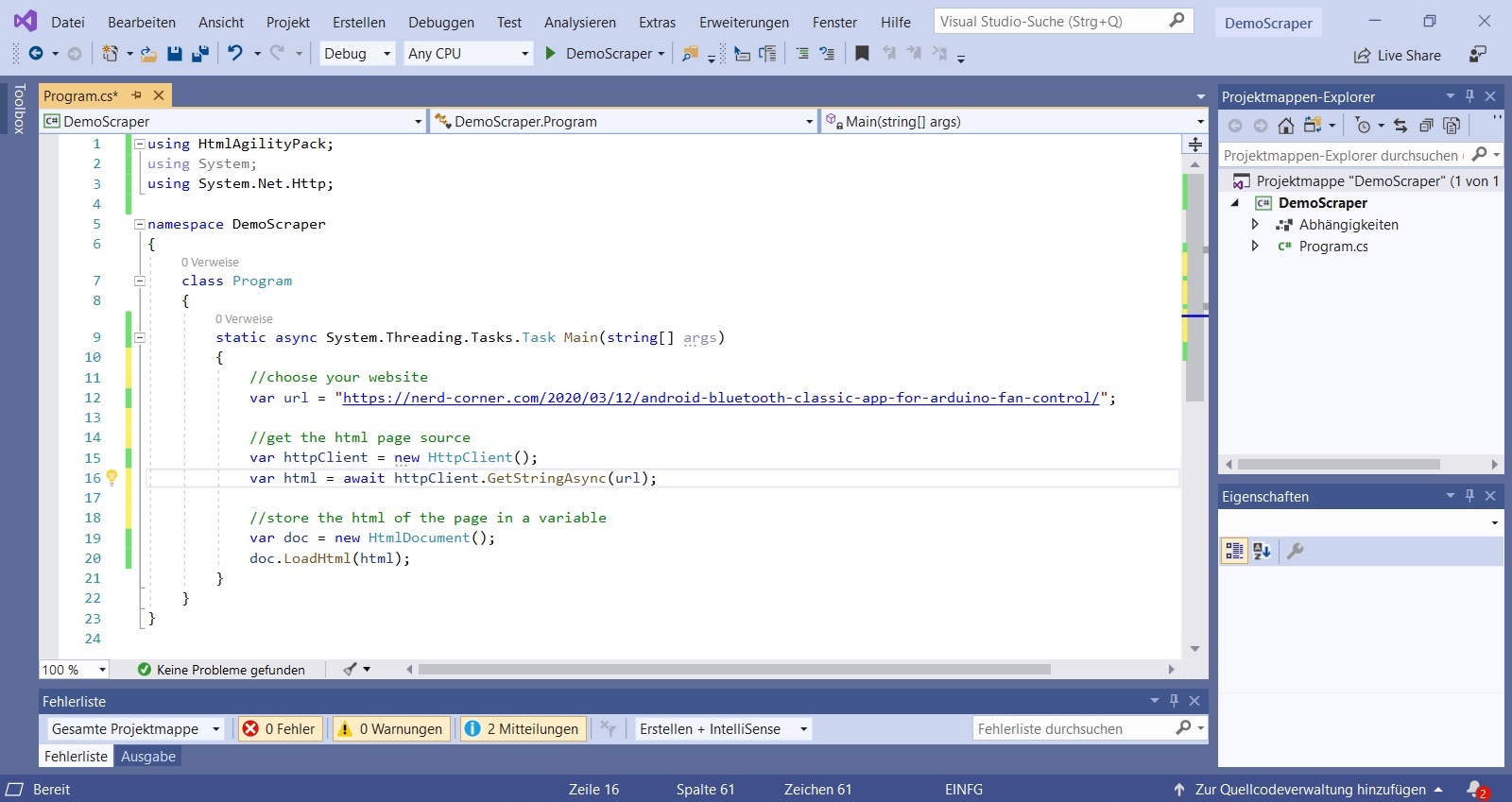
using HtmlAgilityPack;
using System;
using System.Net.Http;
namespace DemoScraper
{
class Program
{
static async System.Threading.Tasks.Task Main(string[] args)
{
//choose your website
var url = "https://nerd-corner.com/android-bluetooth-classic-app-for-arduino-fan-control/";
//get the html page source
var httpClient = new HttpClient();
var html = await httpClient.GetStringAsync(url);
//store the html of the page in a variable
var doc = new HtmlDocument();
doc.LoadHtml(html);
}
}
}
Retrieve data from the website
In fact, the major part has already been done. The source code of the page is loaded into a variable and can now be searched for interesting data.
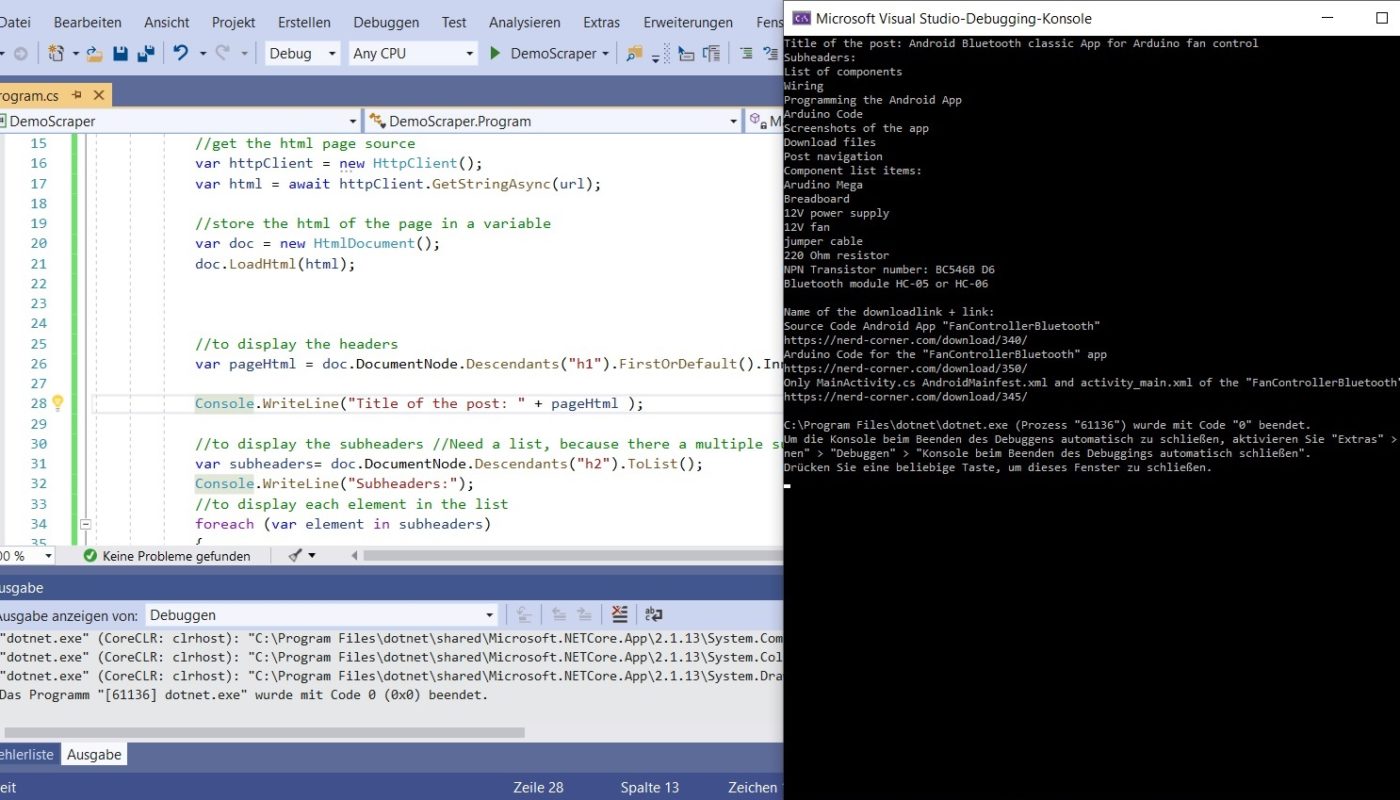
For example, to pull the title of the article, open the browser, right-click on the post title and then select “Inspect”. Now a console opens with the title “Elements” and you are automatically at the position of the title in the HTML code of the website.
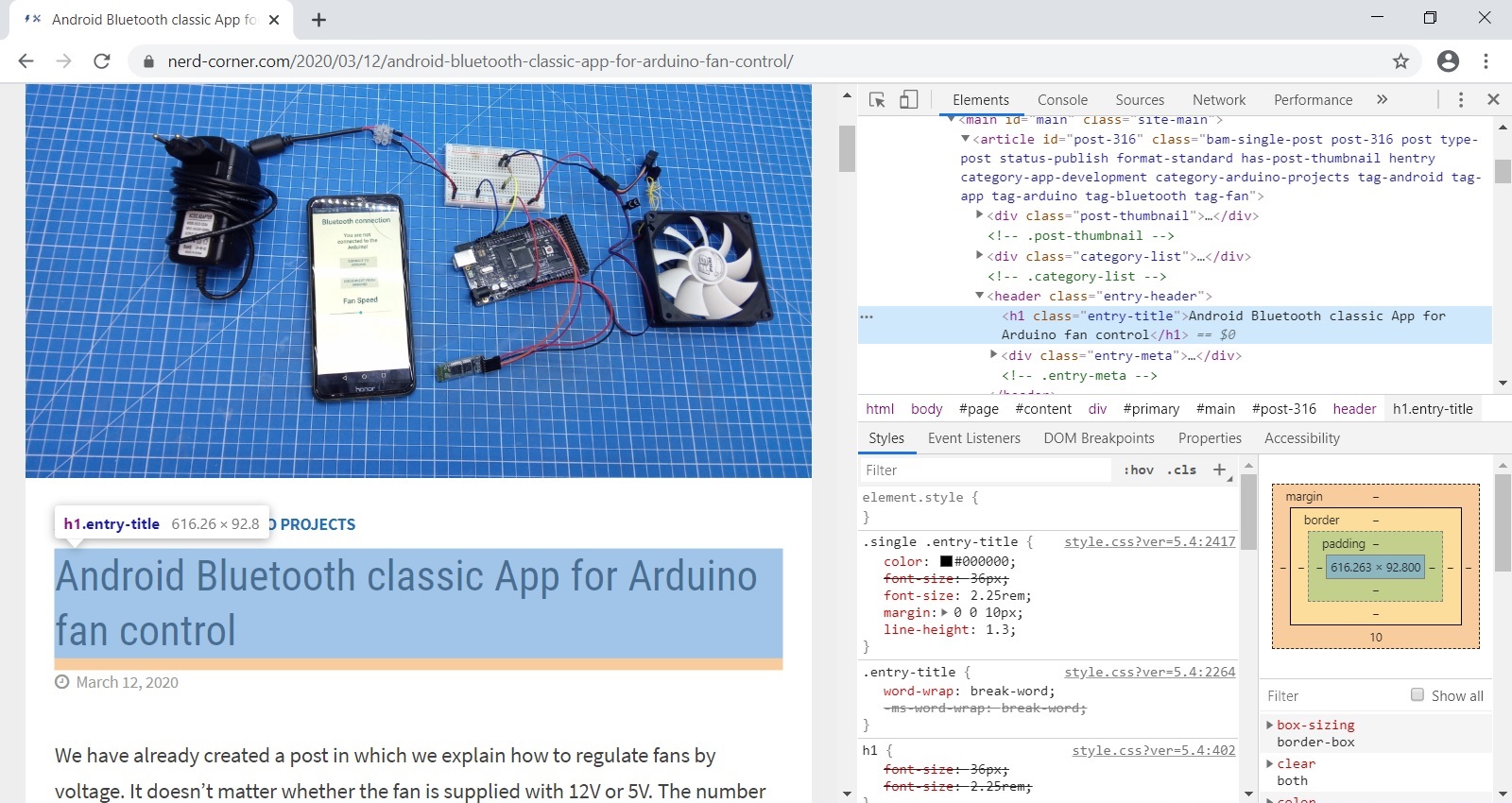
If you take a closer look at the HTML page code, you can see that it is the only <h1> </h1> attribute. So our scraper can easily search in the “doc” variable for “h1” and output the text: “doc.DocumentNode.Descendants (” h1 “). FirstOrDefault (). InnerText;”. “Console.WriteLine” is responsible for the output.
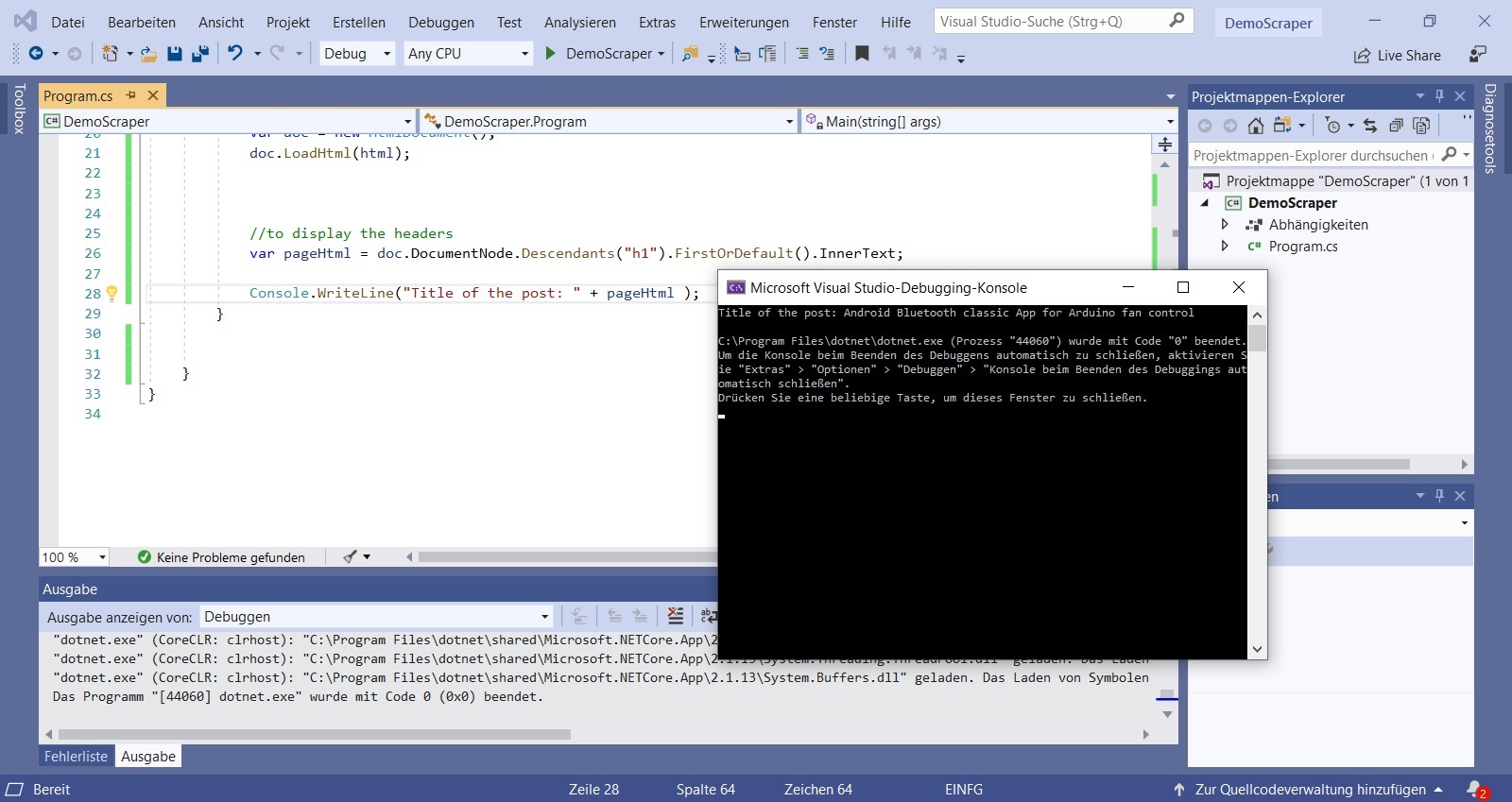
Different methods for a web scraper in C#
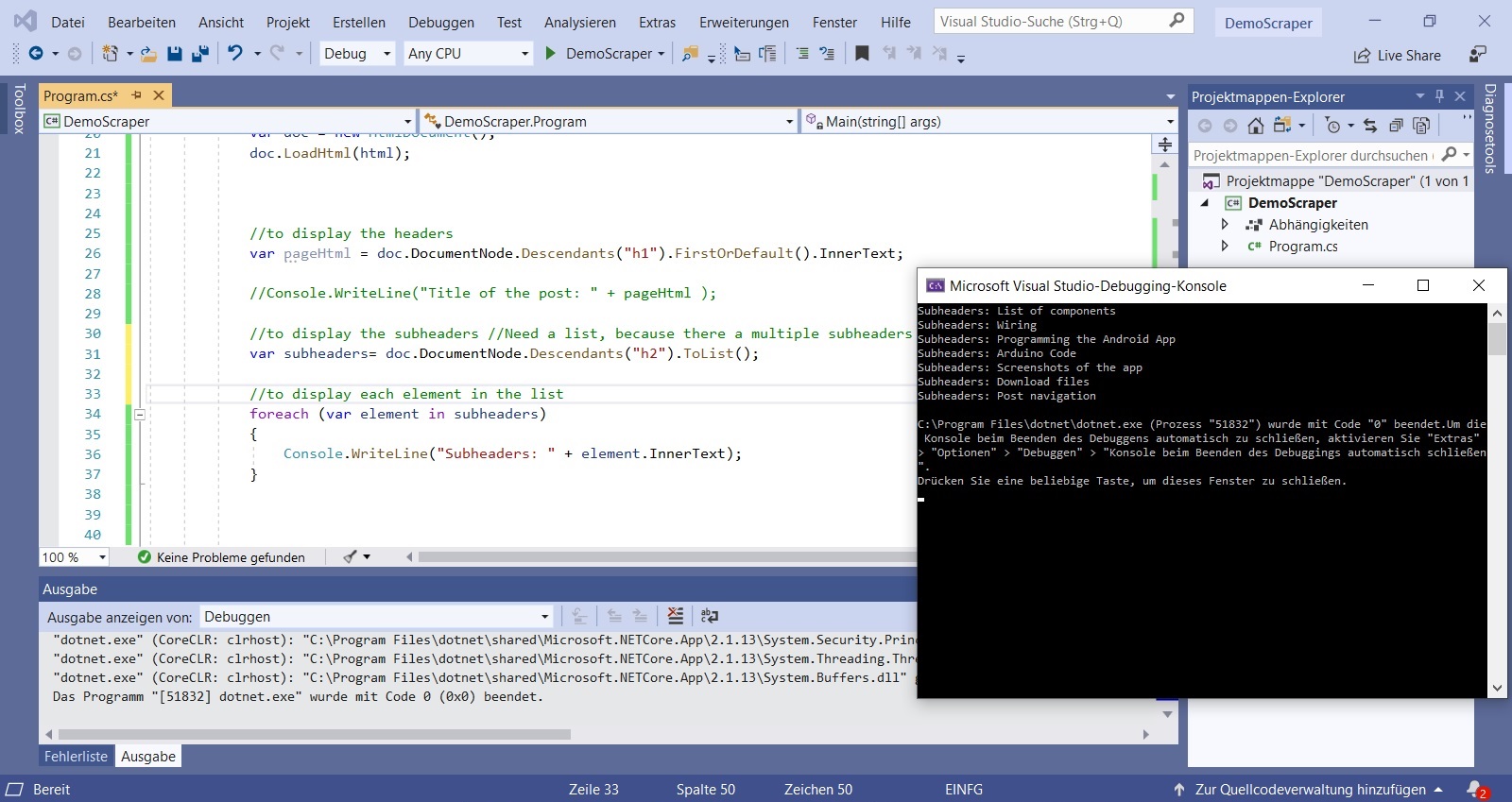
We can do the same to scrape subheadings. The console in the browser shows us the attribute “h2” here. Since there are several subheadings, we need a list element. So the command is:
//to display the subheaders //Need a list, because there a multiple subheaders
var subheaders= doc.DocumentNode.Descendants("h2").ToList();
//to display each element in the list
foreach (var element in subheaders)
{
Console.WriteLine("Subheaders: " + element.InnerText);
}
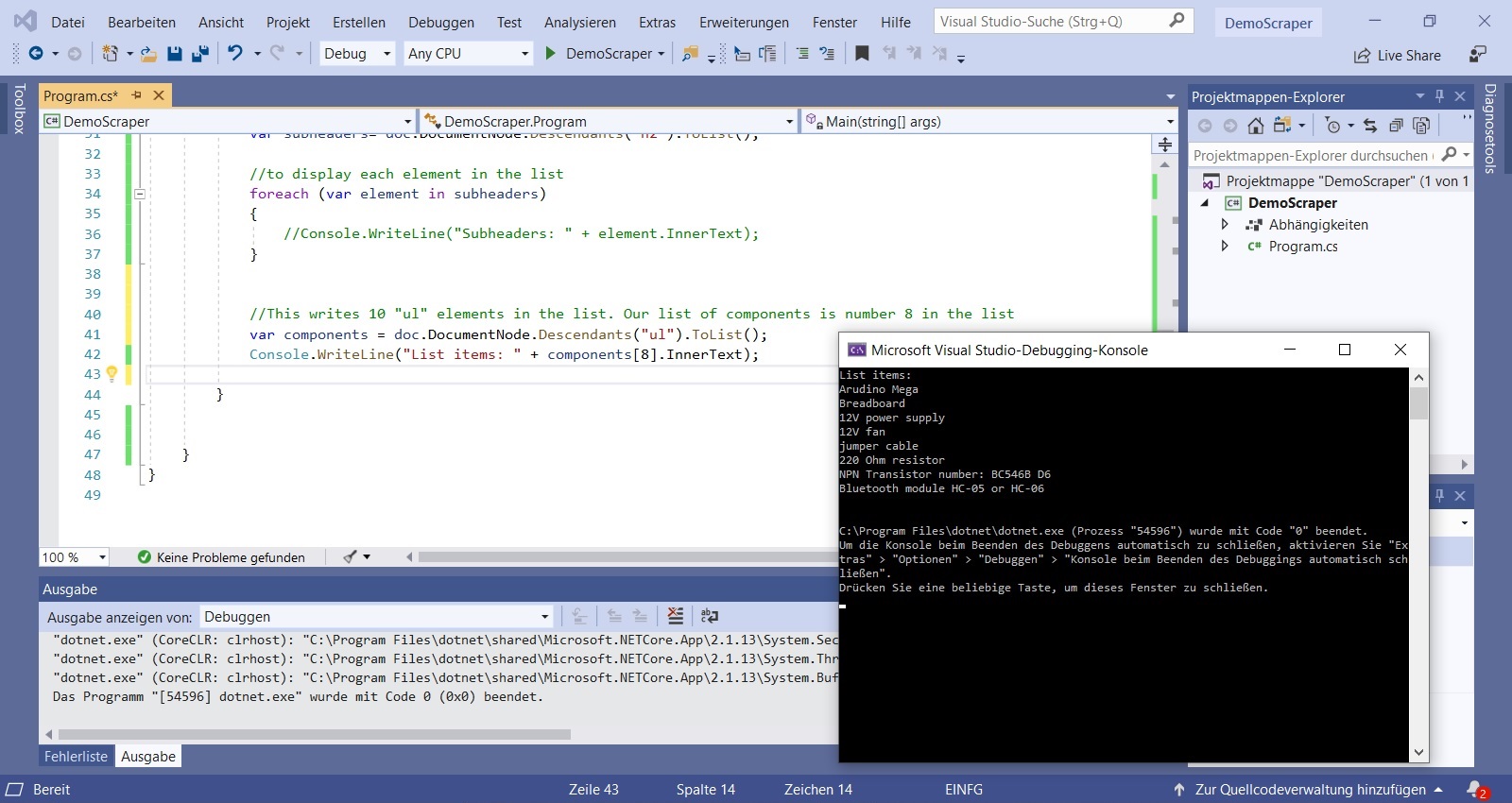
For example, to pull the list of components from the website, we have to search in the HTML code of the page for <ul> </ul>. By the way, “ul” stands for “unordered list”. We have the “ul” tag several times on the website. 10 times in total. For example, at the end of the article in the section “Download Files” is also an “unordered list”. We only look at the 8th entry of the components variable to get the component list and not the other “ul” lists:
//This writes 10 "ul" elements in the list.
//Our list of components is number 8 in the list
var components = doc.DocumentNode.Descendants("ul").ToList();
Console.WriteLine("List items: " + components[8].InnerText);
If you want to scrape the download files, you can simply look at the 9th entry:
//This writes 10 "ul" elements in the list.
//The Download Files are number 9 in the list
var components = doc.DocumentNode.Descendants("ul").ToList();
Console.WriteLine("Download Files: " + components[9].InnerText);However, this method is not very robust. If a little thing on the website changes, like for example one unsorted list will be deleted, it is possible that the scraper no longer works correctly. The “Download Files” can also be displayed in a different way:
//The Download Files are links and the class is called download-links,
//so we search for with this attributes
var downloadFiles = doc.DocumentNode.Descendants("a")
.Where(node=>node.GetAttributeValue("class","").Equals("download-link")).ToList();
//to display each listelement
foreach(var element in downloadFiles)
{
//the name of the file
Console.WriteLine(element.InnerText.Trim('\n','\t'));
//the downloadlink of the file
Console.WriteLine(element.GetAttributeValue("href","").Trim('\n','\t'));
}
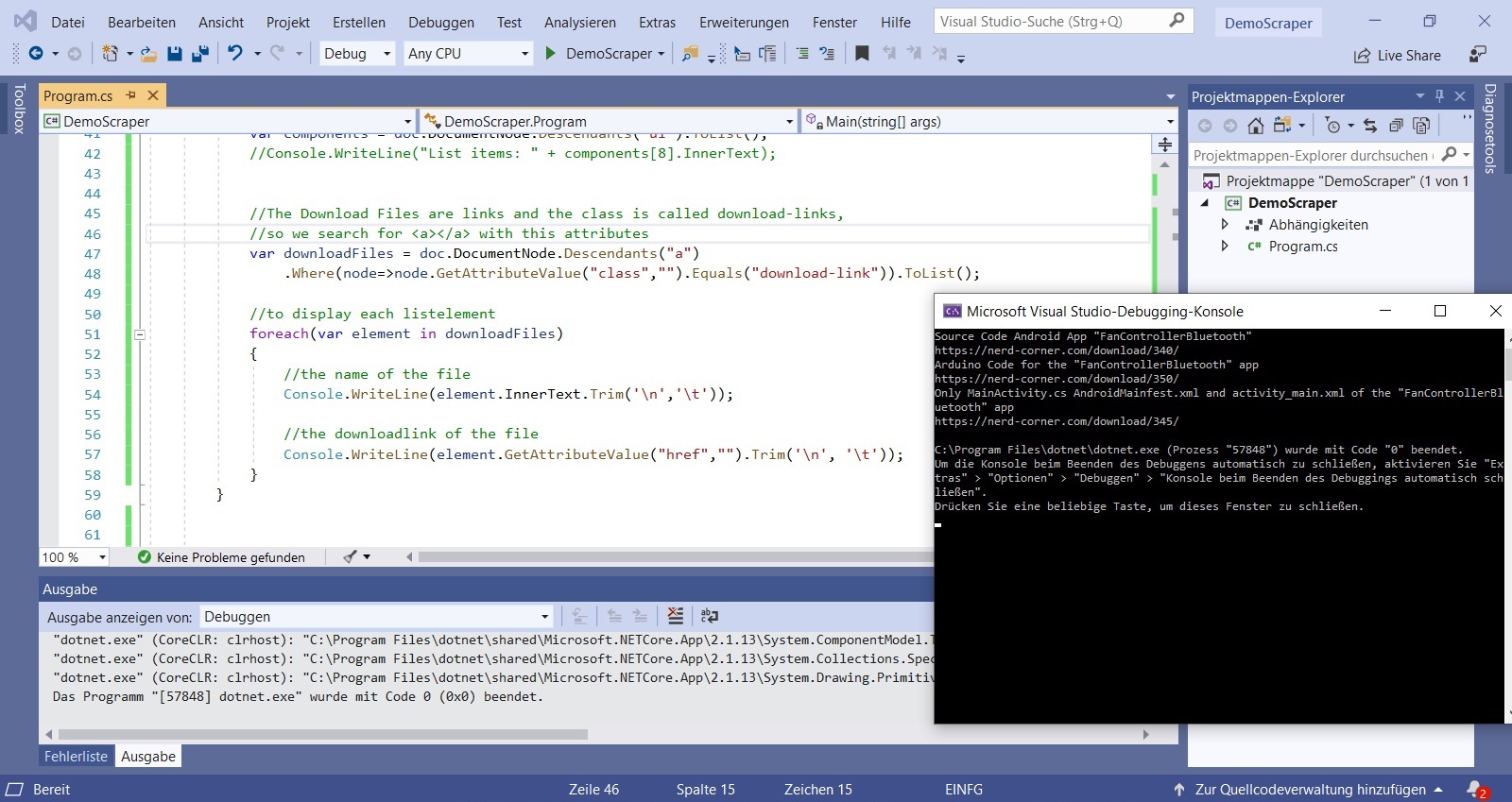
If we browse the “Element Console” for <a> </a>, we get all elements with web links. We also specify the link by looking for these which belong to the “download-link” class. So we get exactly the entries that we wanted. The name of the download link can be displayed with “InnerText” and the download link itself can be obtained with “GetAttributeValue (” href “,” “)”. “Trim” removes unnecessary blank lines and spaces.
Useful tips for a web scraper in C#!
The “Elements Console” does not always show the actual page source text! Sometimes, as for example with Google Maps, additional Java scripts are loaded so that the actual HTML page source text does not correspond to the “Elements Console”. To check, simply right-click and click on “View page source”. The page source html is important. We read this into our .NET application and we search here for the desired information.
The outer shape of the scraped text is often not ideal. There are many spaces, empty lines, shifts or unwanted characters. But you can easily adjust the outer shape:
char[] charsToTrim = { '*', ' ', '\'','\n','\t', '\r', };
Console.WriteLine(element.InnerText.Trim(charsToTrim));

nice artilce , thank you . keep it up
Good article! We are linking to this great post on our website. Keep up the great writing!
It is really interesting to see how you did it in C#, but I think nowadays I would always prefer python for webscraping.
This is excellent. Thank you very much for this. I’m a huge fan of how-to articles on anything re: webscraping, c# or r-pi.